はじめに
この記事ではPythonによるスクレイピングを使って、メルカリでの特定の商品の取引相場を調べるツールを作成する方法を書いていきます。
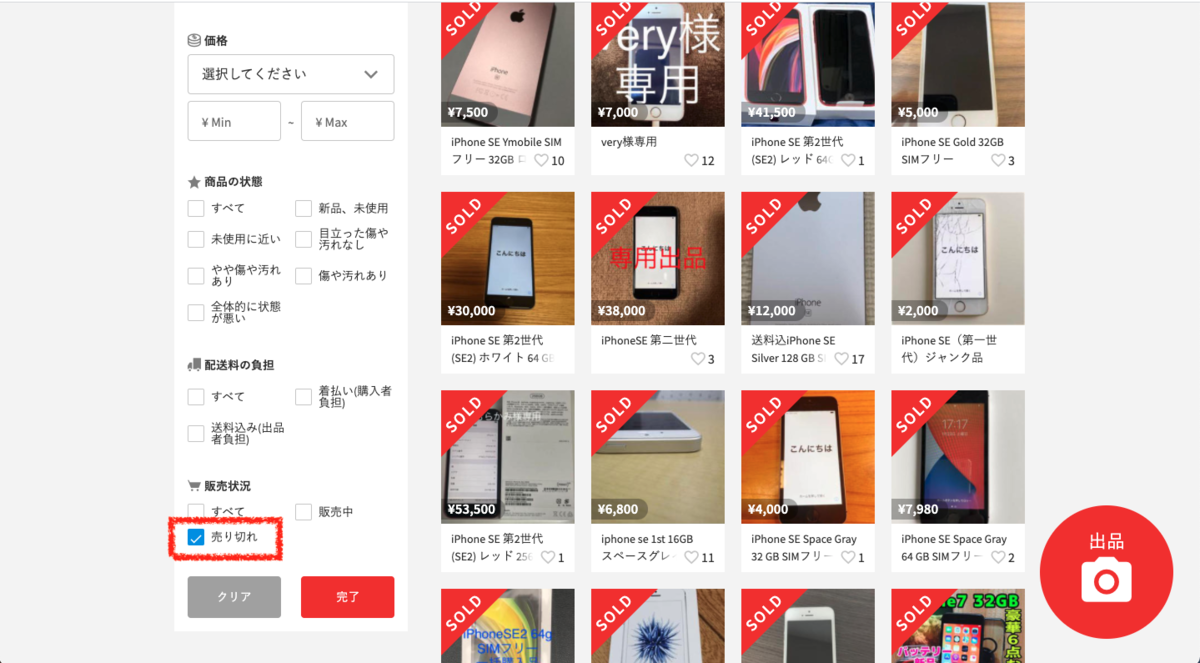
メルカリで出品されている商品の価格帯を知りたいときは、メルカリのページの検索ボックスにキーワードを入れて検索しますよね。
試しに「iphone se simフリー」で検索してみます。

するとこんな感じで商品の画像と値段が表示されてきます。
この検索結果を見ていって大体の値段相場を把握する感じが通常だと思います。

ここでは既に売り切れたものにしぼって商品価格を調べる想定とします。
販売状況のところで「売り切れ」にチェックが入っている状態ですね。
手作業で簡単に実施できるとはいえ、出品されている数が多い商品だったりすると検索結果のページ数も多く、1つ1つ見ていくと結構時間がかかってしまいます。
というわけで、この作業を代わりにpythonにやってもらおうという試みです。
処理の流れ
プログラムの流れですが、
- メルカリのページ上で商品検索するためのキーワードを入力
- ブラウザ(Google chrome)でメルカリのページを開き、入力されたキーワードで商品検索
- 表示された商品の商品名と価格を読み取って記憶し、次のページがあれば開く
- 最終ページまでの各ページを表示して商品名と価格の読み取りを繰り返す
- 読み取った商品名と価格をcsvファイルに書き込んで出力する
こうして作成されたcsvファイルを可視化することで大体の価格帯を掴むことができます。
スクレイピングのコード
実際のコードですが、下のような感じです。
SLACKURL_ex の部分は各自の環境に合わせて編集してください。
slack通知はなくても動作に問題ないので、slack連携関連の部分はなくしちゃっても大丈夫です。
import sys from bs4 import BeautifulSoup from selenium import webdriver import time import os import csv from selenium.webdriver.chrome.options import Options # main処理 def main(): # メルカリのURL BASE_URL = 'https://www.mercari.com' #キーワード読み込み args = sys.argv KEYWORD = args[1] for i in range(2,len(args)): KEYWORD += '+' + args[i] URL_INI = BASE_URL + '/jp/search/?keyword=' + KEYWORD + '&status_trading_sold_out=1' url = URL_INI # 検索結果格納用配列 result_array = [['item_name','item_price','url']] # 次ページ番号格納用 next_page_num = 2 while True: # スクレイピング実行 try: # Chrome設定 options = Options() options.add_argument('--headless') #対象URLにリクエスト driver = webdriver.Chrome(options=options) driver.get(url) time.sleep(5) # 文字コードをUTF-8に変換し、html取得 html = driver.page_source.encode('utf-8') soup = BeautifulSoup(html, "html.parser") # tagとclassを指定して要素を取り出す item_name = soup.find('div', class_='items-box-content clearfix').find_all('h3', class_='items-box-name font-2') item_price = soup.find('div', class_='items-box-content clearfix').find_all('div', class_='items-box-price font-5') item_url = soup.find('div', class_='items-box-content clearfix').find_all('a') pager = soup.find('ul', class_='pager').find_all('a') item_num = len(item_name) for i in range(0,item_num): result_array.append([item_name[i].text, int(item_price[i].text.replace('¥','').replace(',','')), BASE_URL + item_url[i].get('href')]) for x in pager: if x.text == str(next_page_num): next_url = BASE_URL + x.get('href') if next_url == '': break next_page_num += 1 url = next_url next_url = '' print('nextpagenum:'+str(next_page_num)) except Exception as e: message = "[例外発生]"+os.path.basename(__file__)+"\n"+"type:{0}".format(type(e))+"\n"+"args:{0}".format(e.args) print(message) finally: # 起動したChromeを閉じる driver.close() driver.quit() # csvファイルへ書き込み with open('mercari-soldvalue.csv', 'w') as file: writer = csv.writer(file, lineterminator='\n') writer.writerows(result_array) if __name__ == '__main__': main()
スクレイピングプログラムが動作している様子
上に書いたコードを実行するとバックグラウンドでブラウザが起動するのですが、「options.add_argument('--headless')」の行をコメントアウトするとブラウザが動いている様子を見ることができます。
参考として、スクレイピング実行中の様子を記録した動画を載せておきます。
Pythonを使ってメルカリの価格相場を調べる方法
取得したcsvファイルの可視化
次は取得したデータが保存されているcsvファイルをグラフにしてみましょう。
まずはcsvファイルを開いて中身を見てみます。
「item_name」に出品されている商品名、「item_price」に出品されている商品の値段、「url」に出品商品の詳細ページへのリンクが格納されています。

商品名のところを見ると、基本的に検索キーワードで狙った商品(iphone se)のデータが取得できていますが、全く関係なさそうな商品も含まれてしまっていますね。
これは、メルカリで指定したキーワードが各商品の説明欄も含めて検索してひっかけてきているためと思われます。
そこで、このcsvファイルを読み込み、商品名で再度しぼりこみをかけた上でグラフ化します。
csvをグラフにする操作はExcelなどを使用しても良いのですが、ここでは最後までpythonを使ってやってみます。
以下のコードを実行します。
import pandas as pd import matplotlib.pyplot as plt CSV_FILENAME = 'mercari-soldvalue.csv' df = pd.read_csv(CSV_FILENAME, encoding="utf-8") df_edit = df.query('item_name.str.contains("iphone", case=False) and item_name.str.contains("se", case=False)', engine='python') print(df_edit) df_edit.to_csv('edit_' + CSV_FILENAME) # x軸、y軸の表示範囲 plt.xlim(0, 60000) #plt.ylim(0, 300) plt.grid(True) plt.hist(df_edit['item_price'], alpha=1.0, bins=500) plt.show()
「df_edit = df.query('item_name.str.contains("iphone", case=False) and item_name.str.contains("se", case=False)', engine='python')」
の部分で、商品名に「iphone」と「se」が含まれている商品のみを抽出しています。
これを実行すると下のようなグラフになりました。

横軸に価格、縦軸に商品数をとっていますので、7000円〜9000円あたりと40000円〜50000円あたりの価格帯の商品が多いことが分かります。
あんまり細かくデータを見たわけではないのですが、この2つの価格帯はiphone seの世代によって分布しているようです。
1世代目のiphone seだと7000円〜9000円のものが多く、2世代目だと40000円〜50000円が多いみたいですね。