目的
今回はPythonを使って、スプレッドシートに記載されている銘柄を読み込んで株価を調べ、結果をスプレッドシートに反映する、というプログラムを書いていきます。
ここでは以下のようなスプレッドシートを対象にします。

プログラムの流れは以下のようなイメージです。
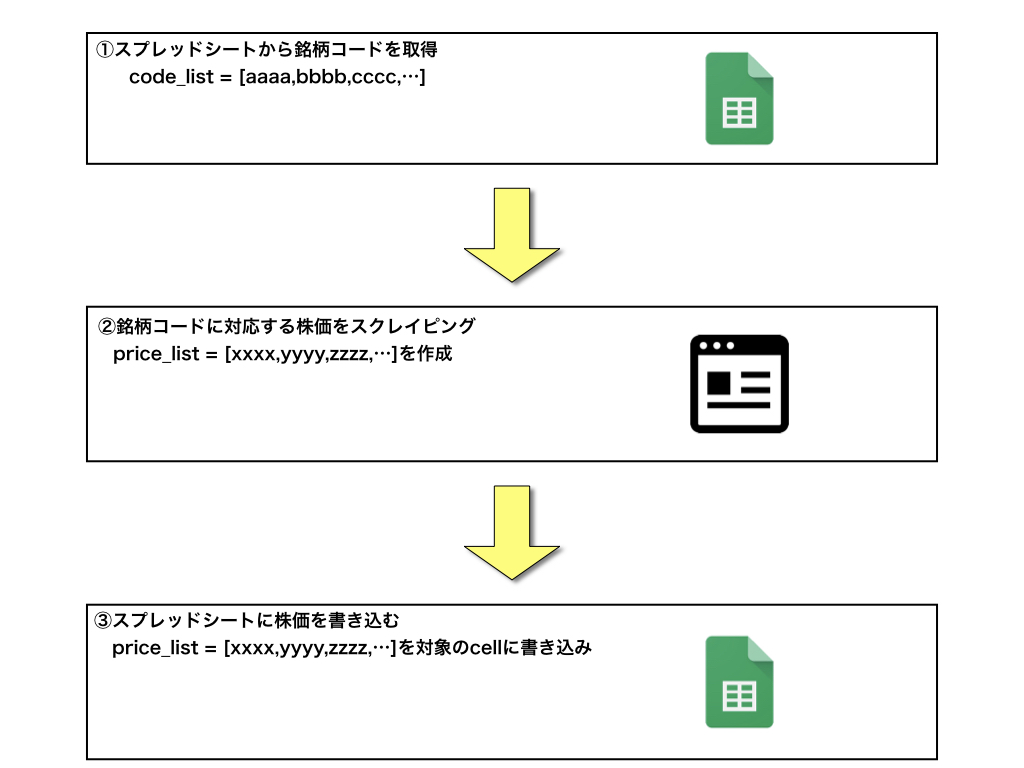
なお、スクレイピングを実行するときは、対象のサイトに迷惑をかけないようにアクセス回数や頻度に注意しましょう。
現実的に人間がアクセスするぐらいの感覚で、アクション一つ一つの間に待ち時間を入れるようにするのが良いと思います。
Pythonのコード
最終的なコードは以下のようになりました。
readSpreadsheet(gc)でスプレッドシートから銘柄コードを読み込んで、スクレイピングを実施。
取得した株価のリスト(price_list)をwriteSpreadsheet(gc, value_list)によってスプレッドシートへ書き込んでいます。
# coding: UTF-8 import gspread from oauth2client.service_account import ServiceAccountCredentials from bs4 import BeautifulSoup import requests import time import slackweb # 例外発生通知用のslackのurl SLACKURL_ex = '各自のslack連携用URLを入れてください' # main処理 def main(): scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] #jsonファイルを指定 credentials = ServiceAccountCredentials.from_json_keyfile_name('各自のjsonファイル名を入れてください', scope) # 認証 gc = gspread.authorize(credentials) # 対象銘柄コード読み取り code_list = readSpreadsheet(gc) # 書き込み対象リスト定義 price_list = [] for i in range(1, len(code_list)): # スクレイピング対象URL URL = 'https://kabutan.jp/stock/?code=' + code_list[i] # スクレイピング実行 try: #対象URLにリクエスト req = requests.get(URL) time.sleep(3) # 文字コードをUTF-8に変換し、html取得 soup = BeautifulSoup(req.text, 'html.parser') # tagとclassを指定して要素を取り出す stock_price = soup.find('div', id='stockinfo_i1').find('span', class_='kabuka').text price_list.append(stock_price.replace('円','')) except Exception as e: message = "[例外発生]stock-price\n"+"type:{0}".format(type(e))+"\n"+"args:{0}".format(e.args) slackweb.Slack(url = SLACKURL_ex).notify(text = message) break # スプレッドシートへ株価を書き込む writeSpreadsheet(gc, price_list) def readSpreadsheet(gc): # 読み込むシートを指定 target_sheet = gc.open('test_sheet').worksheet('stock') # 指定した列のセルの値を読み込む value_list = target_sheet.col_values(1) return value_list def writeSpreadsheet(gc, value_list): # 書き込み対象のシートを指定 target_sheet = gc.open('test_sheet').worksheet('stock') for i in range(0,len(value_list)): #対象のセルに値を書き込む(row, col, value) target_sheet.update_cell(i+2, 3, value_list[i]) if __name__ == '__main__': main()
上記コードでは、スクレイピング中に例外が発生した際にはslackに通知するようにしてみました。
Pythonとslackの連携設定については、以下をご覧ください。
www.77-lifework.com
実際にコードを実行してみると・・・
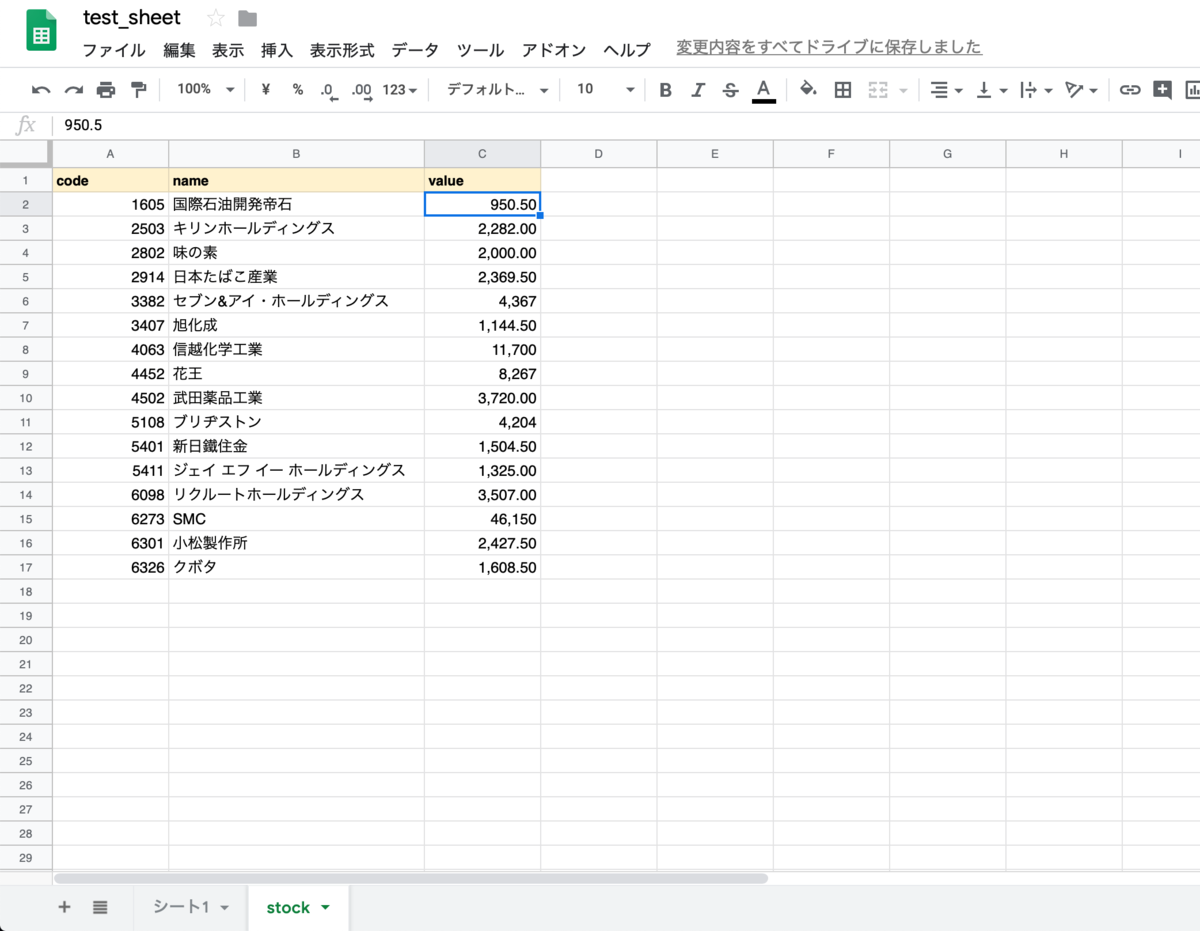
という感じで、株価が記載されています!
ちなみにスクレイピングの対象とするサイトから必要な情報(今回であれば株価)を抽出するときは、ブラウザで対象のページにアクセスし、
ページのソースを確認しましょう。
GoogleChromeであれば、対象のページを開いた状態でキーボードのF12を押すと、ページのソースhtmlを見ることができます。
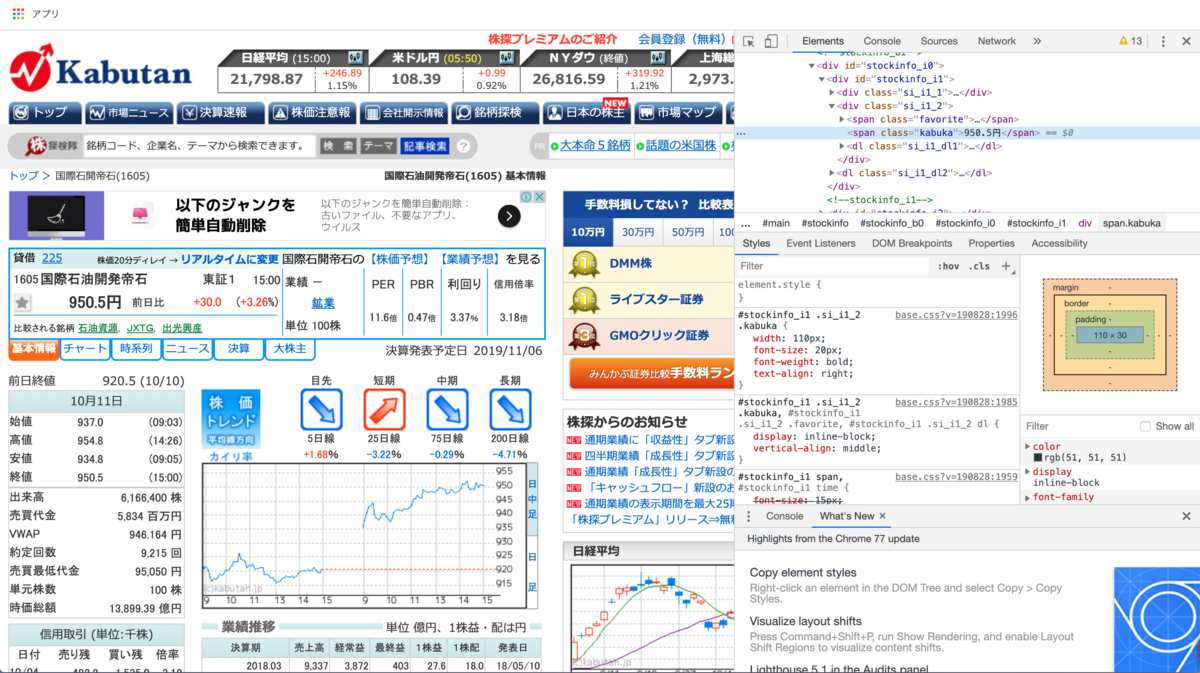
これを見ると、株価の値を取得するには、「 idが 'stockinfo_i1' のdivタグ」配下にある「classが 'kabuka' のspanタグ」を抽出すれば良いことが分かります。
このように、スクレイピングする際には対象のページを確認した上で、どのように必要な情報を取得するか考えてプログラムを組めばOKです。
最後に
これで指定した銘柄の株価をスプレッドシートに反映することができるようになりました。
このプログラムを1日1回自動実行する、など、cronやタスクスケジューラで設定しておけば、自分で調べる手間が省けますね。
最後まで読んでいただき、ありがとうございました。